-
Mark code duplication with a GUID
It's always a trade-off when choosing between code duplication or adding a dependency. The conflict of redundancy vs dependencies.
As it says in The Pragmatic Programmer (one of the best programming books) on "DRY":
DRY (Don't Repeat Yourself) is almost a mantra for developers. But if applied indiscriminately, it leads to abstract code that’s hard to read & understand. It also stops different parts of the code to evolve to their full potential. Do not follow the DRY principle blindly.
Sometimes it's an easy decision, e.g. when the duplication would be inside a single class, then making a new private method inside that class is almost always better than the duplication.
When the decision isn't so easy, e.g. because you'd need to add a new dependency across modules, then you need to think about it a bit more.
If you do decide that duplication is the right thing to do here, then you can mark the duplicated code with a GUID. Doing that means that it's easy to search for that GUID to find the other copies of that duplicated code. Making your life much easier later on when you come back to make another change.
// Duplicated VIP condition code 6b012ccc-2069-466c-8717-2c5999c96eb2 if(AccountIsVip(user)) { // ... }As well as making the duplication easy to find, it also makes it clear that the duplication was intentional, not accidental.
We should all try to avoid unnecessary duplication, but keep in mind that the wrong abstraction can be worse than duplication.
-
Ditto & Beyond Compare to diff clipboard history
Ditto is a great clipboard history (and snippet) app for Windows, and it's on my "must install" list for setting up a new PC.
One of the lesser-known features of Ditto is the ability to diff clipboard items. You select two items from your clipboard history, then press Ctrl+F2 to diff them. If it's the two most recent clipboard items you want to compare, then it's nice and quick from the keyboard:
- Press your "activate Ditto" shortcut (e.g. Ctrl+Shift+V). This will already have the most recent item selected.
- Hold shift, then press the down arrow. This will keep the first item selected, and also select the one bellow it.
- Press Ctrl+F2.
This will try to launch WinMerge (or open the website if you don't have it), but I prefer Beyond Compare as my diff tool. Thankfully, you can choose that in the advanced options for Ditto:
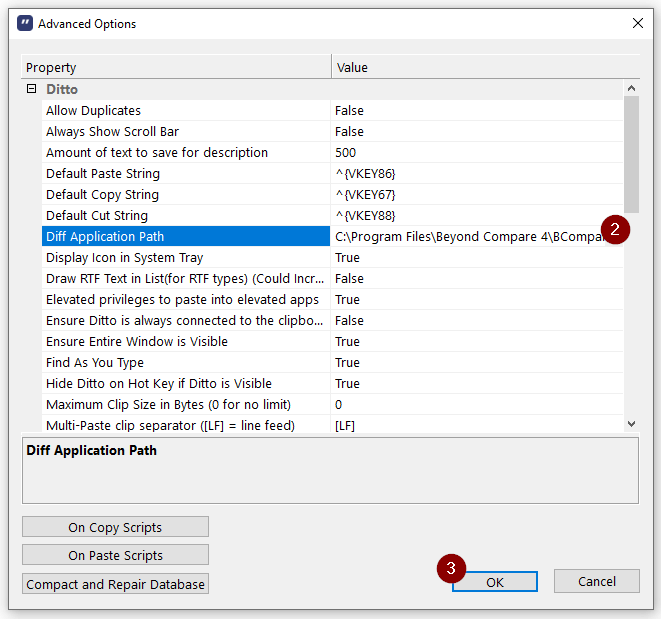
I know Beyond Compare has its own clipboard tool, but it's not as versatile (or as reliable) as Ditto.
-
Prioritising bugs
The priority for fixing a bug should be a function of several things:
- When this bug happens, how bad is the impact? ("Severity")
- How often does this bug happen? ("Frequency")
- How much effort would be required to fix this bug? ("Cost")
- What is the risk of fixing this bug? ("Risk")
Two of them are "user questions" (Severity and Frequency), and the other two are "developer questions" (Cost and Risk). Questions 1 and 2 are about the importance of fixing a bug. The answers to Questions 3 and 4 can only make the priority of a bug go down, never up. If the answers to 1 and 2 make it obvious that a bug doesn’t deserve attention, then questions 3 and 4 don’t need to be asked – they are just there for when the first two questions come out with "need to fix this".
A crash is obviously very severe, no matter what the cause. If you lose data because of the crash, that makes it even worse. But I can think of things worse that than that, such as giving the wrong result to some calculation. If a crash happens on a limited set of data, that reduces the frequency of it – so a crash that happens every time you do X is more imporant than crash that happens every time you do X with data Y.
-
ICanHasCheezburger interface naming style
One of the things I often struggle with when writing code is naming things. Naming things well is especially important for interfaces, they're likely used in more places than the concrete types in a loosely coupled OO system.
One guideline I've found that helps me is something I like to call the "ICanHasCheezburger naming style". I typically start all my interface names with I (most of my code is C# at the moment), so that part is easy - after that, you just describe the specific reason that the interface exists.
So, if you're writing something for getting the GPS location on a phone - instead of calling the interface something like
ILocationManager, call itIProvideLocationorILookupLocation. It makes it very clear to anyone reading the code what the responsibility of that interface.Sometimes I might write a single concrete class implementing more than one of these interfaces, because they pretty much always end up as Role Interfaces and that's fine. I like to keep my interfaces narrow if I can. However, the main thing this avoids is accidentally bloating the interface as time goes on. It's much harder to allow yourself to expand the scope of something called
IProvideLocationthan it is to expanded the scope ofILocationManager- which means you end up following the Interface segregation principle with very little effort. -
UK "bank grade" SSL
After reading Troy Hunt's "Do you really want “bank grade” security in your SSL? Here’s how Aussie banks fare" post, it made me wonder how well banks do over here in the UK. I'm expecting them to be about the same, because I can't think of a reasons for UK banking to be particularly better or worse than Aussie banks.
After dropping a few bank URL in to the SSL Labs test, showing the same properties as Troy, we get:
Bank Grade Still supports SSL 3 Still supports SHA1 No TLS 1.2 support Still supports RC4 Forward secrecy support POODLE vulnerable Santander B Pass Pass Pass Fail Fail Pass Barclays B Pass Fail Pass Fail Fail Pass Co-operative Bank B Pass Pass Fail Fail Fail Pass Royal Bank of Scotland B Pass Fail Fail Pass Fail Pass HSBC B Fail Fail Fail Fail Fail Pass Lloyds C Fail Fail Fail Fail Fail Fail I know Santander isn't a UK bank, but it s popular bank on the UK high-street.
It's nice to see there's no F grades here, but the lack of A grades is disappointing - as is the POODLE vulnerability with Lloyds. Hopfully they'll work to fix that in the near future.
-
Richard Feynman and Specification by Example
I think Richard Feynman would have been a fan of Specification by Example
Taken from Surely You're Joking Mr Feynman
I had a scheme, which I still use today when somebody is explaining something that I'm trying to understand: I keep making up examples. For instance, the mathematicians would come in with a terrific theorem, and they're all excited. As they're telling me the conditions of the theorem, I construct something which fits all the conditions. You know, you have a set (one ball) - disjoint (two balls). Then the balls turn colors, grow hairs, or whatever, in my head as they put more conditions on. Finally they state the theorem, which is some dumb thing about the ball which isn't true for my hairy green ball thing, so I say, "False!"
If it's true, they get all excited, and I let them go on for a while. Then I point out my counterexample.
"Oh. We forgot to tell you that it's Class 2 Hausdorff homomorphic."
"Well, then," I say, "It's trivial! It's trivial!"
-
Refactoring in the past with git
Sometimes you get half way through a task when you realise you need to do some refactoring before you can continue. One option is to just do the refactoring as you go, but if it's more than a trivial refactoring that will make it hard work for anyone reviewing the code. They'll need to untangle the refactoring from the feature implementation.
If you're using git, you have another option. Commit your unfinished work as "WIP" on a new branch then checkout the previous commit - the one before you started this task.
Then you can do the refactoring without your feature work getting in the way. When you've finished, you just commit that refactoring work with a nice commit message and then switch back your WIP branch.
Once you've done that, you can rebase your WIP onto the refactoring work and carry on where you left off.
It's as if you travelled back in time to do the refactoring just before you needed it.
-
NSubstitute speed-bumps when using Returns()
When using NSubstitute, to make it possible to do things like
substitute.Foo().Returns(7), callingFoo()on a substitute sets some internal state that says "Next timeReturns()is called, I'm the method you're setting the return value on". This means that if you call anything on any substitute inside a call toReturns()you'll end up in a mess.I've ran into problems with this when doing stuff like:
substitute.Foo().Returns(CreateSomethingThatUsesNSubstitute())This kind of problem can take a while to track down. To fix it, you need to assign the result of
CreateSomethingThatUsesNSubstitute()to a local first. e.g.var theResult = CreateSomethingThatUsesNSubstitute(); thing.Foo().Returns(theResult)Once you've done that, everything should work as expected.
-
Maze refactoring challenge (C#)
A long time ago, when I was new to the concept of refactoring code, one of the practice projects that I tried was cleaning up some really horrible maze generating code. “Horrible” in that it was a BASIC program ported to Java.
Also a long time ago, I converted that Java port over to C#. If you want to try that version yourself, you can get the code from GitHub.
-
Methods should “do one thing”
I’d often come across the advice that methods (and classes) should “only do one thing”. That advice seemed almost ridiculous to me. e.g. saving to a file, you need to
- Open the file
- Write the data
- Close the file
So that’s three things. Then there’s error handling on top of that, which should count as another ‘thing’. So I could never see how to follow that advice.
However, I’d seen this guideline often enough that I also thought "a large group of smart programmers seem to believe this is a good idea". I’m (hopefully) not an idiot, so I was clearly missing something here.
It wasn’t until reading Clean Code earlier this year that it finally clicked.
What “doing one thing” really means
Clean Code talks about “doing one thing” in terms of levels of abstraction. This makes much more sense to me. Everything inside a method should be one level of abstraction below the method itself, which also means everything inside the method should be at the same level of abstraction. As Clean Code says:
“If a function does only those steps that are one level of abstraction below the stated name of the function, then the function is doing one thing. After all, the reason we have functions is to decompose a larger concept (in other words, the name of the function) into a set of steps at the next level of abstraction.”
After it clicked, I switched to thinking about it as meaning "one level of abstraction per method" which is something I can both understand, and agree with. It’s still hard to follow that guideline all the time, but at least I now know what I’m aiming for. Which is pretty close to what I’d been aiming for already.
As Clean Code also says:
“Mixing levels of abstraction within a function is confusing. Readers may not be able to tell whether a particular expression is an essential concept or a detail. Worse, like broken windows, once details are mixed with essential concepts, more and more details tend to accrete within the function.”